library(dplyr)
library(car)
library(readxl)
library(factoextra)
library(FactoMineR)
library(remotes)
library(factoextra)
library(corrplot)L’énigme des oeufs de coucou : une analyse comparative
Comparaison des longueurs d’œufs selon l’espèce hôte : approche par ANOVA
Exercice 1 - L’énigme des oeufs de coucou
Les packages qui seront utiles pour cet exercice.
Le coucou européen ne couve pas ses propres oeufs, mais les dépose dans les nids d’oiseaux d’autres espèces. Des études antérieures ont montré que les coucous ont parfois évolué pour pondre des oeufs dont la couleur est similaire à celle des oeufs de l’espèce hôte.
Est-ce également le cas pour la taille des oeufs ? Les coucous pondent-ils des oeufs de taille similaire à ceux de leurs hôtes ?

Le fichier de données est cuckooeggs.csv
cuckooeggs = read.csv("data_raw/cuckooeggs.csv")
head(cuckooeggs) host_species egg_length
1 Hedge Sparrow 20.85
2 Hedge Sparrow 21.65
3 Hedge Sparrow 22.05
4 Hedge Sparrow 22.85
5 Hedge Sparrow 23.05
6 Hedge Sparrow 23.05summary(cuckooeggs) host_species egg_length
Length:120 Min. :19.65
Class :character 1st Qu.:21.85
Mode :character Median :22.35
Mean :22.46
3rd Qu.:23.25
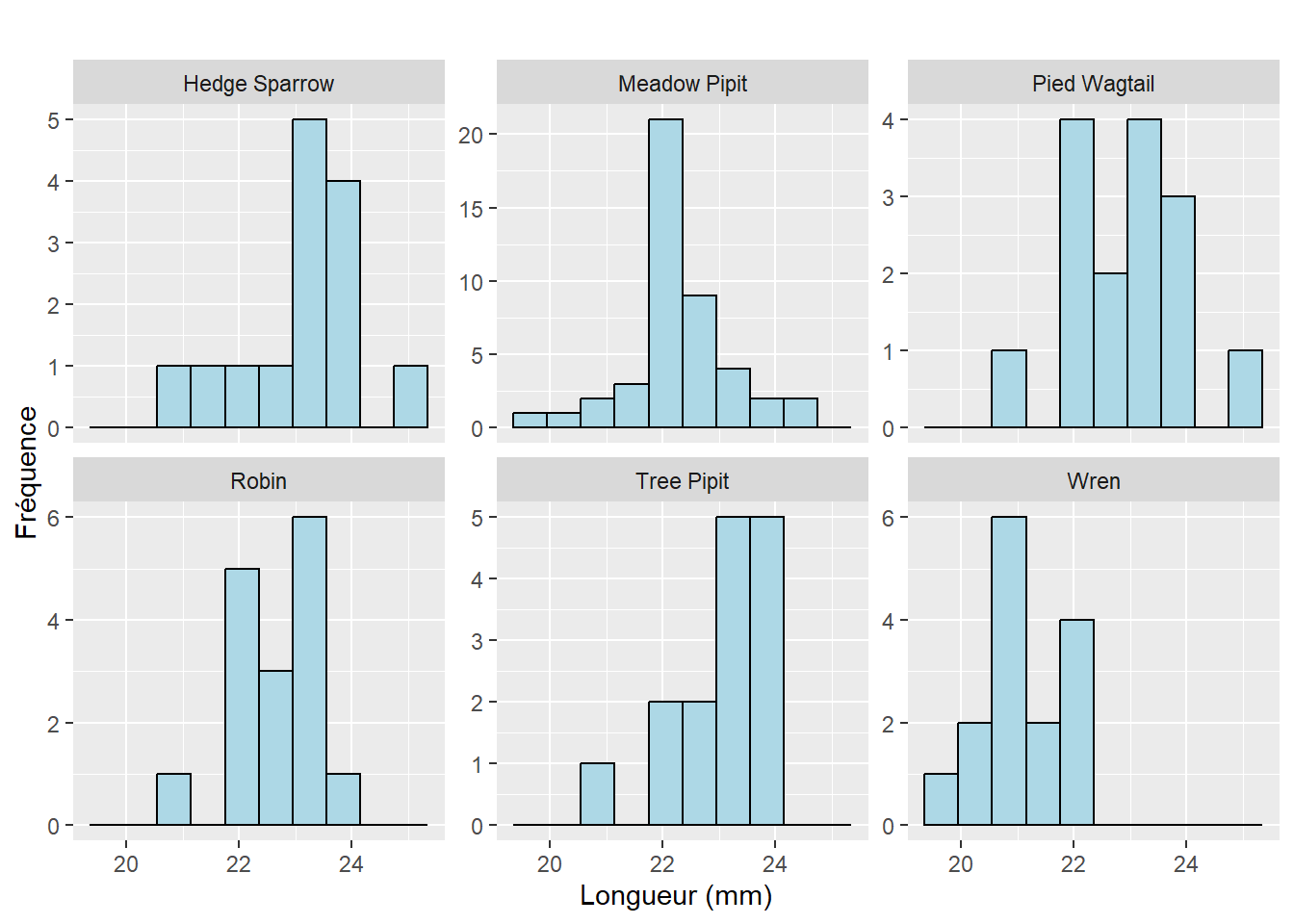
Max. :25.05 Nous traçons quelques graphiques ci-dessous.
library(ggplot2)
ggplot(cuckooeggs, aes(x = egg_length)) +
geom_histogram(bins = 10, fill = "lightblue", color = "black") +
facet_wrap(~ host_species, scales = "free_y") +
labs(
title = "",
x = "Longueur (mm)", y = "Fréquence"
)
On demande à R de nous donner les moyennes et les écarts types de la longueur des oeufs pour chacune des espèces hotes.
stats <- cuckooeggs %>%
group_by(host_species) %>%
summarise(
Moyenne = mean(egg_length),
Ecart_type = sd(egg_length),
n = n()
)
stats# A tibble: 6 × 4
host_species Moyenne Ecart_type n
<chr> <dbl> <dbl> <int>
1 Hedge Sparrow 23.1 1.07 14
2 Meadow Pipit 22.3 0.921 45
3 Pied Wagtail 22.9 1.07 15
4 Robin 22.6 0.685 16
5 Tree Pipit 23.1 0.901 15
6 Wren 21.1 0.744 15On se propose, afin de savoir si les coucous pondent des oeufs de tailles différentes selon l’espèce hôte, de réaliser un T-test.
t.test(egg_length ~ host_species, data = cuckooeggs)
On tente alors de réaliser une ANOVA.
Sur conseil d’un collaborateur on réalise un leveneTest.
leveneTest(egg_length ~ host_species, data = cuckooeggs)Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 5 0.6397 0.6698
114 Ce collaborateur nous recommande vivement d’effectuer un shapiro.test. Nous en réalisons donc plusieurs.
by(cuckooeggs$egg_length, cuckooeggs$host_species, shapiro.test)cuckooeggs$host_species: Hedge Sparrow
Shapiro-Wilk normality test
data: dd[x, ]
W = 0.94843, p-value = 0.5366
------------------------------------------------------------
cuckooeggs$host_species: Meadow Pipit
Shapiro-Wilk normality test
data: dd[x, ]
W = 0.93006, p-value = 0.009424
------------------------------------------------------------
cuckooeggs$host_species: Pied Wagtail
Shapiro-Wilk normality test
data: dd[x, ]
W = 0.96471, p-value = 0.7736
------------------------------------------------------------
cuckooeggs$host_species: Robin
Shapiro-Wilk normality test
data: dd[x, ]
W = 0.95212, p-value = 0.5239
------------------------------------------------------------
cuckooeggs$host_species: Tree Pipit
Shapiro-Wilk normality test
data: dd[x, ]
W = 0.89772, p-value = 0.08786
------------------------------------------------------------
cuckooeggs$host_species: Wren
Shapiro-Wilk normality test
data: dd[x, ]
W = 0.93295, p-value = 0.3019anova_res <- aov(egg_length ~ host_species, data = cuckooeggs)
shapiro.test(residuals(anova_res))
Shapiro-Wilk normality test
data: residuals(anova_res)
W = 0.9804, p-value = 0.07761Une fois nos shapiro.test réalisés, un autre collaborateur examine notre travail et nous indique qu’il aurait été pertinent de produire un qqplot. Nous tentons alors de tracer ce graphique.
qqnorm(residuals(anova_res))
qqline(residuals(anova_res))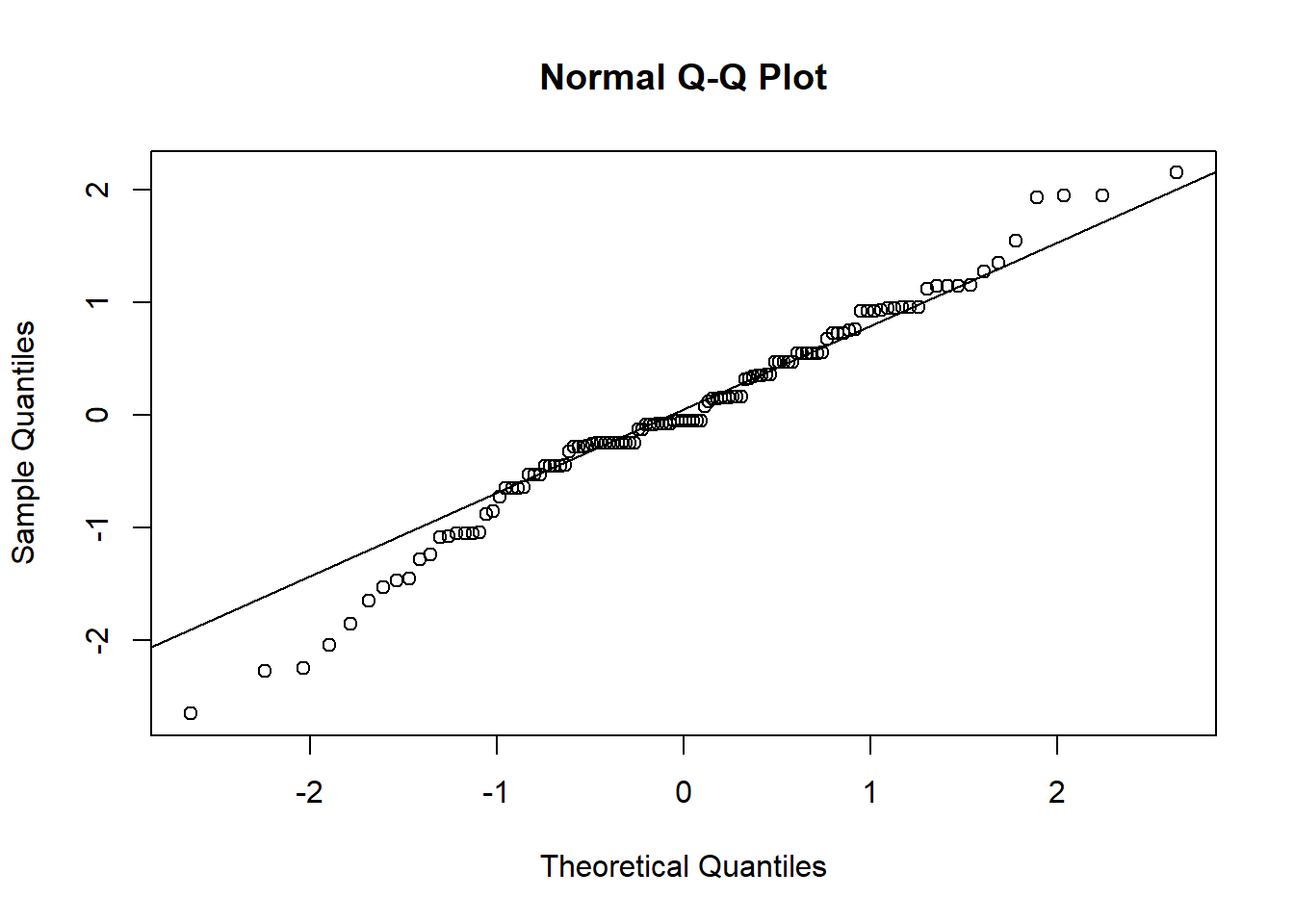
summary(anova_res) Df Sum Sq Mean Sq F value Pr(>F)
host_species 5 42.94 8.588 10.39 3.15e-08 ***
Residuals 114 94.25 0.827
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Toujours le même collaborateur nous parle déffecteuer un test post hoc. On le réalise sans trop savoir ce que l’on est en train de tester.
tukey <- TukeyHSD(anova_res)
tukey Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = egg_length ~ host_species, data = cuckooeggs)
$host_species
diff lwr upr p adj
Meadow Pipit-Hedge Sparrow -0.82253968 -1.629133605 -0.01594576 0.0428621
Pied Wagtail-Hedge Sparrow -0.21809524 -1.197559436 0.76136896 0.9872190
Robin-Hedge Sparrow -0.54642857 -1.511003196 0.41814605 0.5726153
Tree Pipit-Hedge Sparrow -0.03142857 -1.010892769 0.94803563 0.9999990
Wren-Hedge Sparrow -1.99142857 -2.970892769 -1.01196437 0.0000006
Pied Wagtail-Meadow Pipit 0.60444444 -0.181375330 1.39026422 0.2324603
Robin-Meadow Pipit 0.27611111 -0.491069969 1.04329219 0.9021876
Tree Pipit-Meadow Pipit 0.79111111 0.005291337 1.57693089 0.0474619
Wren-Meadow Pipit -1.16888889 -1.954708663 -0.38306911 0.0004861
Robin-Pied Wagtail -0.32833333 -1.275604766 0.61893810 0.9155004
Tree Pipit-Pied Wagtail 0.18666667 -0.775762072 1.14909541 0.9932186
Wren-Pied Wagtail -1.77333333 -2.735762072 -0.81090459 0.0000070
Tree Pipit-Robin 0.51500000 -0.432271433 1.46227143 0.6159630
Wren-Robin -1.44500000 -2.392271433 -0.49772857 0.0003183
Wren-Tree Pipit -1.96000000 -2.922428738 -0.99757126 0.0000006